Was Sie vorher wissen sollten
bevor Sie beginnen
Beginnt 21 July 2026 14:20
Endet 21 July 2026
Deep Reinforcement Learning: From Theory to Practice
University of Colorado Boulder
41 Kurse
The University of Colorado Boulder, often referred to as CU Boulder, offers a wide range of educational programs and courses, both in-person and online. Students can choose from a variety of study tracks, including courses in the arts, science, engineering, business and more.
Online University of Colorado Boulder Сourses
One of the key benefits of CU Boulder is the ability to take courses online. This is a great opportunity for students who want a quality education but prefer flexibility in their schedule. CU Boulder's online courses provide access to highly qualified faculty and the most up-to-date materials.
Summer courses at the University of Colorado Boulder
Summer is a great time to explore new topics and expand your knowledge. The University of Colorado Boulder offers a variety of summer courses both online and in-person. This is an excellent opportunity for students to spend their summer usefully by studying subjects of interest.
Best CU Boulder Courses for Students
CU Boulder not only offers a wide variety of programs, but also a high-quality education. Students can choose from a variety of courses, from basic to advanced, to develop their skills and interests. The university actively uses innovative approaches to teaching, such as AI Education, which helps students gain up-to-date knowledge.
Courses at CU Boulder: More with Free Lessons
With a variety of free courses at CU Boulder, students can expand their knowledge in a variety of areas. These courses are available for both beginners and advanced students, allowing everyone to find a suitable training option to suit their interests.
Pluses of studying online courses at the University of Colorado Boulder
The University of Colorado Boulder provides students with a unique opportunity to study through online courses, which has a number of significant advantages.
Firstly, the advantage of studying online courses at the University of Colorado Boulder is the flexible schedule. Students can choose their own time to study material and watch lectures, making it easier for them to balance their studies with other responsibilities such as work or family commitments. This flexibility makes education more accessible to a wider range of people.
Secondly, University of Colorado Boulder courses provide students with the opportunity to study unique material presented by experienced teachers. Through access to experts in various fields of knowledge, students can gain relevant knowledge and skills that will be useful in the modern world.
The third benefit of taking CU Boulder online courses is the opportunity to connect and collaborate with other students from different countries and cultures. This contributes to an enriching educational experience by allowing students to be exposed to different points of view and broaden their horizons.
Additionally, University of Colorado Boulder online courses typically offer a variety of interactive learning materials, making the learning process more fun and effective. Students can learn through video lectures, tests, forums, and other innovative methods that stimulate learning.
Thus, taking University of Colorado Boulder online courses offers students many benefits, including flexible scheduling, access to experts, international communication, and an interactive educational approach. This is an excellent opportunity for students to receive a quality education, expand their knowledge and skills, and prepare for the challenges of the modern world.
Conclusion
The University of Colorado Boulder is a place where students can receive a quality education with a variety of courses and programs to choose from. Whether you're looking for online or in-person training, summer courses or free programs, CU Boulder offers ample opportunities for development and learning!
6 weeks, 2 hours a week
Optionales Upgrade verfügbar
Mittelstufe
Lernen Sie in Ihrem eigenen Tempo
Paid Course
Optionales Upgrade verfügbar
Übersicht
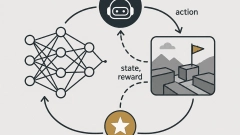
How can reinforcement learning scale beyond small tabular problems to high-dimensional environments such as games, robotics, and autonomous decision-making? This course introduces deep reinforcement learning, where reinforcement-learning algorithms are combined with neural-network-based function approximation.
Learners begin by studying why tabular methods break down in large or continuous state spaces and how value functions, action-value functions, and policies can be represented by parameterized models. The course then develops value-based deep reinforcement learning methods, including fitted value iteration, Deep Q-Networks, replay buffers, target networks, Double DQN, dueling networks, and prioritized experience replay.
Learners also study direct policy optimization through policy-gradient methods such as REINFORCE, as well as actor–critic methods that combine policy optimization with value estimation. The course introduces selected modern deep RL algorithms, such as PPO, DDPG, and SAC, with emphasis on implementation, stability, diagnosis, and empirical evaluation.
By the end of the course, learners will be able to implement deep reinforcement-learning agents, diagnose common sources of instability, evaluate learned behavior using suitable experimental protocols, and report results in a reproducible way. This course can be taken for academic credit as part of CU Boulder’s Masters of Science in Computer Science (MS-CS) and Master of Science in Artificial Intelligence (MS-AI) degrees offered on the Coursera platform.
These fully accredited graduate degrees offer targeted courses, short 8-week sessions, and pay-as-you-go tuition. Admission is based on performance in three preliminary courses, not academic history.
CU degrees on Coursera are ideal for recent graduates or working professionals. Learn more:
MS in Artificial Intelligence:
https:
//www.coursera.org/degrees/ms-artificial-intelligence-boulder MS in Computer Science:
https:
//coursera.org/degrees/ms-computer-science-boulder
Lehrplan
- Function Approximation for RL
- Deep Q-Learning and Value-Based Deep RL
- Policy Gradients and REINFORCE
- Actor-Critic Methods
- Modern Deep RL: PPO, DDPG, and SAC
- Practical Deep RL Implementation
Unterrichtet von
Ashutosh Trivedi
Fachgebiete
Computer Science