Qué necesitas saber antes de
comenzar
Inicio 21 July 2026 10:52
Fin 21 July 2026
Aprendizaje por Refuerzo Profundo: De la Teoría a la Práctica
University of Colorado Boulder
41 Cursos
La Universidad de Colorado Boulder, a menudo referida como CU Boulder, ofrece una amplia gama de programas educativos y cursos, tanto presenciales como en línea. Los estudiantes pueden elegir entre una variedad de pistas de estudio, incluyendo cursos de artes, ciencias, ingeniería, negocios y más.
Cursos en línea de la Universidad de Colorado Boulder
Una de las principales ventajas de CU Boulder es la posibilidad de tomar cursos en línea. Esta es una excelente oportunidad para los estudiantes que desean una educación de calidad pero prefieren flexibilidad en su horario. Los cursos en línea de CU Boulder brindan acceso a profesores altamente calificados y los materiales más actualizados.
Cursos de verano en la Universidad de Colorado Boulder
El verano es un excelente momento para explorar nuevos temas y expandir tus conocimientos. La Universidad de Colorado Boulder ofrece una variedad de cursos de verano, tanto en línea como presenciales. Esta es una excelente oportunidad para que los estudiantes pasen su verano productivamente estudiando temas de interés.
Mejores cursos de CU Boulder para estudiantes
CU Boulder no solo ofrece una amplia variedad de programas, sino también una educación de alta calidad. Los estudiantes pueden elegir entre una variedad de cursos, desde básicos hasta avanzados, para desarrollar sus habilidades e intereses. La universidad utiliza activamente enfoques innovadores para la enseñanza, como la Educación IA, que ayuda a los estudiantes a adquirir conocimientos actualizados.
Cursos en CU Boulder: Más con Clases Gratuitas
Con una variedad de cursos gratuitos en CU Boulder, los estudiantes pueden expandir sus conocimientos en una variedad de áreas. Estos cursos están disponibles tanto para principiantes como para estudiantes avanzados, permitiendo a todos encontrar una opción de formación adecuada a sus intereses.
Ventajas de estudiar cursos en línea en la Universidad de Colorado Boulder
La Universidad de Colorado Boulder brinda a los estudiantes una oportunidad única para estudiar a través de cursos en línea, lo cual tiene una serie de ventajas significativas.
En primer lugar, la ventaja de estudiar cursos en línea en la Universidad de Colorado Boulder es el horario flexible. Los estudiantes pueden elegir su propio tiempo para estudiar el material y ver las conferencias, lo que facilita el equilibrio de sus estudios con otras responsabilidades, como el trabajo o los compromisos familiares. Esta flexibilidad hace que la educación sea más accesible para un rango más amplio de personas.
En segundo lugar, los cursos de la Universidad de Colorado Boulder brindan a los estudiantes la oportunidad de estudiar material único presentado por profesores experimentados. A través del acceso a expertos en varios campos del conocimiento, los estudiantes pueden adquirir conocimientos y habilidades relevantes que serán útiles en el mundo moderno.
El tercer beneficio de tomar cursos en línea de CU Boulder es la oportunidad de conectarse y colaborar con otros estudiantes de diferentes países y culturas. Esto contribuye a una enriquecedora experiencia educativa al permitir que los estudiantes se expongan a diferentes puntos de vista y amplíen sus horizontes.
Además, los cursos en línea de la Universidad de Colorado Boulder suelen ofrecer una variedad de materiales de aprendizaje interactivos, lo que hace que el proceso de aprendizaje sea más divertido y efectivo. Los estudiantes pueden aprender a través de videoconferencias, pruebas, foros y otros métodos innovadores que estimulan el aprendizaje.
Por lo tanto, tomar cursos en línea de la Universidad de Colorado Boulder ofrece a los estudiantes muchos beneficios, incluyendo programación flexible, acceso a expertos, comunicación internacional y un enfoque educativo interactivo. Esta es una excelente oportunidad para que los estudiantes reciban una educación de calidad, expandan sus conocimientos y habilidades, y se preparen para los desafíos del mundo moderno.
Conclusión
La Universidad de Colorado Boulder es un lugar donde los estudiantes pueden recibir una educación de calidad con una variedad de cursos y programas para elegir. Ya sea que estés buscando formación en línea o presencial, cursos de verano o programas gratuitos, CU Boulder ofrece amplias oportunidades para el desarrollo y el aprendizaje!
6 weeks, 2 hours a week
Actualización opcional disponible
Intermedio
Avanza a tu propio ritmo
Paid Course
Actualización opcional disponible
Resumen
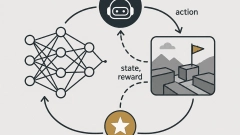
How can reinforcement learning scale beyond small tabular problems to high-dimensional environments such as games, robotics, and autonomous decision-making? This course introduces deep reinforcement learning, where reinforcement-learning algorithms are combined with neural-network-based function approximation.
Learners begin by studying why tabular methods break down in large or continuous state spaces and how value functions, action-value functions, and policies can be represented by parameterized models. The course then develops value-based deep reinforcement learning methods, including fitted value iteration, Deep Q-Networks, replay buffers, target networks, Double DQN, dueling networks, and prioritized experience replay.
Learners also study direct policy optimization through policy-gradient methods such as REINFORCE, as well as actor–critic methods that combine policy optimization with value estimation. The course introduces selected modern deep RL algorithms, such as PPO, DDPG, and SAC, with emphasis on implementation, stability, diagnosis, and empirical evaluation.
By the end of the course, learners will be able to implement deep reinforcement-learning agents, diagnose common sources of instability, evaluate learned behavior using suitable experimental protocols, and report results in a reproducible way. This course can be taken for academic credit as part of CU Boulder’s Masters of Science in Computer Science (MS-CS) and Master of Science in Artificial Intelligence (MS-AI) degrees offered on the Coursera platform.
These fully accredited graduate degrees offer targeted courses, short 8-week sessions, and pay-as-you-go tuition. Admission is based on performance in three preliminary courses, not academic history.
CU degrees on Coursera are ideal for recent graduates or working professionals. Learn more:
MS in Artificial Intelligence:
https:
//www.coursera.org/degrees/ms-artificial-intelligence-boulder MS in Computer Science:
https:
//coursera.org/degrees/ms-computer-science-boulder
Programa
- Aproximación de Funciones para RL
- Aprendizaje profundo Q y RL profundo basado en valores
- Gradientes de Políticas y REINFORCE
- Métodos Actor-Crítico
- RL Profundo Moderno: PPO, DDPG, y SAC
- Implementación Práctica de RL Profundo
Impartido por
Ashutosh Trivedi
Materias
Computer Science