Ce que vous devez savoir avant
Vous commencez
Débute 21 July 2026 10:52
Se termine 21 July 2026
Apprentissage par Renforcement Profond : de la Théorie à la Pratique
University of Colorado Boulder
41 Cours
L'Université de Colorado Boulder, souvent appelée CU Boulder, propose une grande variété de programmes et de cours éducatifs, à la fois en personne et en ligne. Les étudiants peuvent choisir parmi diverses filières d'études, notamment des cours d'arts, de sciences, d'ingénierie, de commerce et plus encore.
Cours en ligne de l'Université de Colorado Boulder
L'un des principaux avantages de la CU Boulder est la possibilité de suivre des cours en ligne. C'est une formidable opportunité pour les étudiants qui veulent une éducation de qualité mais préfèrent avoir de la flexibilité dans leur emploi du temps. Les cours en ligne de la CU Boulder donnent accès à des professeurs hautement qualifiés et aux matériels les plus récents.
Cours d'été à l'Université de Colorado Boulder
L'été est un excellent moment pour explorer de nouveaux sujets et élargir ses connaissances. L'Université de Colorado Boulder propose une variété de cours d'été en ligne et en personne. C'est une excellente opportunité pour les étudiants de passer leur été utilement en étudiant des sujets qu'ils aiment.
Meilleurs cours de la CU Boulder pour les étudiants
La CU Boulder offre non seulement une grande variété de programmes, mais aussi une éducation de haute qualité. Les étudiants peuvent choisir parmi une variété de cours, du niveau basique au niveau avancé, pour développer leurs compétences et leurs centres d'intérêt. L'université utilise activement des approches innovantes dans l'enseignement, comme l'éducation par l'IA, qui aide les étudiants à acquérir des connaissances à jour.
Cours à la CU Boulder : Plus avec des leçons gratuites
Grâce à une variété de cours gratuits à la CU Boulder, les étudiants peuvent élargir leurs connaissances dans de nombreux domaines. Ces cours sont disponibles pour les étudiants débutants et avancés, permettant à chacun de trouver une option de formation adaptée à ses intérêts.
Avantages de suivre des cours en ligne à l'Université de Colorado Boulder
L'Université de Colorado Boulder offre aux étudiants une opportunité unique d'étudier à travers des cours en ligne, qui présentent un certain nombre d'avantages importants.
Premièrement, l'avantage d'étudier les cours en ligne à l'Université de Colorado Boulder est la flexibilité de l'horaire. Les étudiants peuvent choisir leur propre moment pour étudier le matériel et regarder les cours, ce qui leur facilite l'équilibre entre leurs études et d'autres responsabilités telles que le travail ou les engagements familiaux. Cette flexibilité rend l'éducation plus accessible à un plus grand nombre de personnes.
Deuxièmement, les cours de l'Université de Colorado Boulder offrent aux étudiants l'opportunité d'étudier un matériel unique présenté par des enseignants expérimentés. Grâce à l'accès à des experts dans divers domaines de la connaissance, les étudiants peuvent acquérir des connaissances et des compétences pertinentes qui seront utiles dans le monde moderne.
Le troisième avantage de suivre les cours en ligne de la CU Boulder est l'occasion de se connecter et de collaborer avec d'autres étudiants de différents pays et cultures. Cela contribue à enrichir l'expérience éducative en permettant aux étudiants d'être exposés à différents points de vue et d'élargir leurs horizons.
En outre, les cours en ligne de l'Université de Colorado Boulder offrent généralement une variété de matériel d'apprentissage interactif, rendant le processus d'apprentissage plus amusant et efficace. Les étudiants peuvent apprendre grâce à des conférences vidéo, des tests, des forums et d'autres méthodes innovantes qui stimulent l'apprentissage.
Ainsi, suivre des cours en ligne de l'Université de Colorado Boulder offre aux étudiants de nombreux avantages, y compris une programmation flexible, l'accès à des experts, la communication internationale, et une approche éducative interactive. C'est une excellente occasion pour les étudiants de recevoir une éducation de qualité, d'élargir leurs connaissances et compétences, et de se préparer aux défis du monde moderne.
Conclusion
L'Université de Colorado Boulder est un endroit où les étudiants peuvent recevoir une éducation de qualité avec une variété de cours et de programmes au choix. Que vous cherchiez une formation en ligne ou en personne, des cours d'été ou des programmes gratuits, la CU Boulder offre de nombreuses opportunités pour le développement et l'apprentissage!
6 weeks, 2 hours a week
Amélioration optionnelle disponible
Intermédiaire
Progressez à votre rythme
Paid Course
Amélioration optionnelle disponible
Aperçu
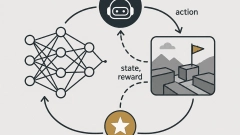
How can reinforcement learning scale beyond small tabular problems to high-dimensional environments such as games, robotics, and autonomous decision-making? This course introduces deep reinforcement learning, where reinforcement-learning algorithms are combined with neural-network-based function approximation.
Learners begin by studying why tabular methods break down in large or continuous state spaces and how value functions, action-value functions, and policies can be represented by parameterized models. The course then develops value-based deep reinforcement learning methods, including fitted value iteration, Deep Q-Networks, replay buffers, target networks, Double DQN, dueling networks, and prioritized experience replay.
Learners also study direct policy optimization through policy-gradient methods such as REINFORCE, as well as actor–critic methods that combine policy optimization with value estimation. The course introduces selected modern deep RL algorithms, such as PPO, DDPG, and SAC, with emphasis on implementation, stability, diagnosis, and empirical evaluation.
By the end of the course, learners will be able to implement deep reinforcement-learning agents, diagnose common sources of instability, evaluate learned behavior using suitable experimental protocols, and report results in a reproducible way. This course can be taken for academic credit as part of CU Boulder’s Masters of Science in Computer Science (MS-CS) and Master of Science in Artificial Intelligence (MS-AI) degrees offered on the Coursera platform.
These fully accredited graduate degrees offer targeted courses, short 8-week sessions, and pay-as-you-go tuition. Admission is based on performance in three preliminary courses, not academic history.
CU degrees on Coursera are ideal for recent graduates or working professionals. Learn more:
MS in Artificial Intelligence:
https:
//www.coursera.org/degrees/ms-artificial-intelligence-boulder MS in Computer Science:
https:
//coursera.org/degrees/ms-computer-science-boulder
Programme
- Approximation de fonctions pour l'apprentissage par renforcement
- Deep Q-Learning et Apprentissage Profond Basé sur la Valeur
- Gradients de Politique et REINFORCE
- Méthodes Acteur-Critic
- Apprentissage par Renforcement Profond Moderne : PPO, DDPG, et SAC
- Implémentation Pratique de l'Apprentissage par Renforcement Profond
Enseigné par
Ashutosh Trivedi
Matières
Computer Science